News
OpenAI Adds New Canvas Feature To Its ChatGPT Interface
The collaborative work tool can be used for both writing and coding projects.
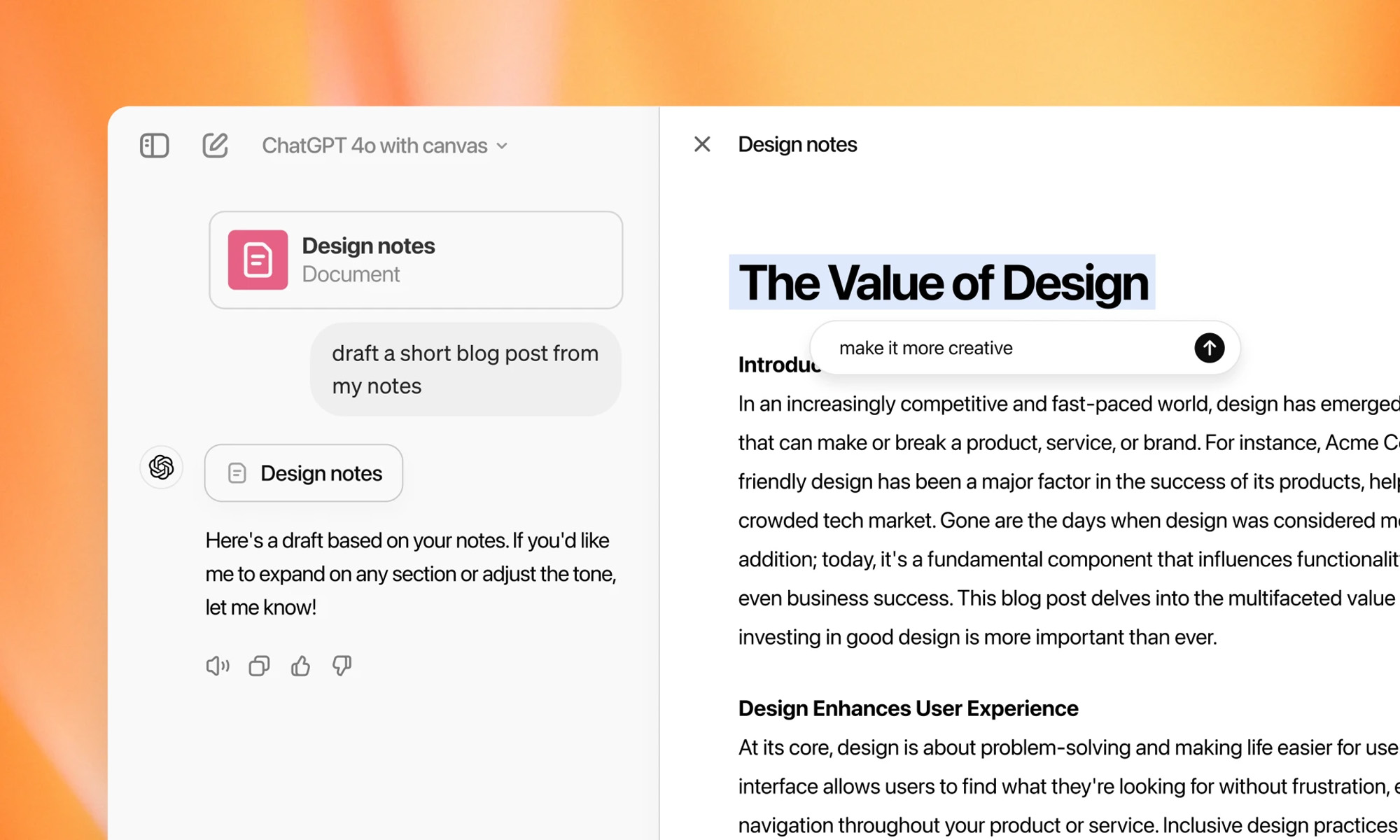
OpenAI has launched a new workspace tool for ChatGPT known as Canvas. The feature, introduced in a recent blog post, is now accessible to ChatGPT Plus and Team subscribers, with Enterprise and Edu users set to gain access next week.
Canvas provides a dedicated virtual space for writing and coding projects, allowing users to collaborate more efficiently with ChatGPT. It opens a separate window next to the chat interface, where users can place writing or code and select specific sections for the model to review. OpenAI describes it as functioning like a “copy editor or code reviewer”.
For writing tasks, ChatGPT can offer suggestions for edits, change text length, or adjust reading levels. It can even add relevant emojis for emphasis and color. Coders benefit from inline recommendations, debugging help, and the ability to translate code into various programming languages such as JavaScript, Python, or C++.
Also Read: Top Free AI Chatbots Available In The Middle East
With the introduction of Canvas, OpenAI has aligned ChatGPT with similar AI tools, such as Anthropic’s Artifacts and Cursor, which focus on project-specific workspaces.



News
A Three-Clinic Network Bets Dubai Is Ready For Longevity Medicine
Longevium has enlisted nearly 100 clinicians and created an AI platform in a bid to sell biological-age tracking as a medicine, not a wellness service.

Dubai has been busily creating the scaffolding for a longevity industry, including a dedicated regulatory authority and a health market deep enough to sustain it. Now the clinics are arriving.
Longevium, a longevity clinic network, has opened three locations across the city: a flagship at Triple Seven Mall on Jumeirah 3, and branches in Jumeirah Lake Towers and Jumeirah Village Circle. Together they house a multidisciplinary team of nearly 100 physicians and specialists offering what the company bills as “a measurable medical system for longevity”.

The pitch is that longevity medicine should look less like a wellness menu and more like continuous clinical care. Each patient’s biological age assessment, laboratory results, body composition, cardiovascular risk factors, metabolic markers, and lifestyle data feed into a single profile, with a proprietary AI platform helping physicians track progress and adjust protocols against the patient’s own biomarkers.
“Healthy aging must be approached clinically through diagnostics, biomarkers, physician supervision, longitudinal tracking, and protocols tailored to the individual,” said Dr. Ksenia Butova, Longevium’s founder and CEO. “Our goal is to help patients understand their health trajectory before disease develops, and then actively change that trajectory”.
The treatment list spans peptide-based protocols, exosome therapies, stem cell approaches, GLP-1 metabolic optimization, hormone balance programs, cardiovascular prevention, and regenerative aesthetics — a model built for the entrepreneurs, executives, and international patients the clinic says want measurable results rather than generic wellness. A signature offering, Longevity Day, compresses biomarker testing, ultrasound and vascular imaging, specialist consultations, IV therapy, and a personalized optimization roadmap into a single three-hour visit.
Also Read: Dubai Certifies The World’s First Purpose-Built Air Taxi Vertiport
“Here, longevity, biotechnology, AI, prevention, and regenerative medicine are converging into a single ecosystem,” said Butova. “This is why Longevium was built in Dubai, and why we believe the UAE can become a global reference point for longevity medicine”.
The emirate established the Dubai Longevity Authority in 2026 to oversee its longevity, wellness, and advanced health sectors, and the Dubai Health Authority reported insured beneficiaries exceeding 4.9 million in 2025, up around 6.5%, with insurance claims reaching approximately 49.6 million, up around 13.5%.

A Three-Clinic Network Bets Dubai Is Ready For Longevity Medicine

YouTube Rolls Out Supervised Children’s Accounts Across MENA

Meta’s New AI Tool Builds Images From Public Instagram Photos

Tamper With The Recording LED & Meta’s Glasses Kill Camera

Samsung’s Next Unpacked Could Bring Two Galaxy Z Fold 8 Models

LUVED Is A New Curated Preloved Marketplace For The UAE

Can AI Save Your Relationship? This New “Wingman” App Thinks It Can
WhatsApp Usernames Are Coming: Here’s How To Claim Yours

Dubai Certifies The World’s First Purpose-Built Air Taxi Vertiport

OpenAI Cleared To Launch GPT-5.6 Publicly After Government Review

-

 News2 months ago
News2 months agoDJI Teases Dual-Camera Osmo Pocket 4P For 2026 Launch
-

 Web32 months ago
Web32 months ago2026 Crypto Trends: Bitcoin, ETFs & The Future Of Payments
-

 News2 months ago
News2 months agoLebanon Ministers Meet Visa Over National Digital Payment Platform
-

 News2 months ago
News2 months agoAt I/O 2026, Sundar Pichai Concedes AI Must Deliver Real Value