News
NVIDIA’s RTX 50-Series Laptop GPUs Bring Blackwell To Mobile
The company promises improved performance and efficiency, with up to 24GB of GDDR7 RAM for the flagship model.

NVIDIA has unveiled its RTX 50-series (Blackwell) GPUs for laptops alongside the desktop lineup, promising impressive performance gains without compromising efficiency. The next-gen hardware features powerful upgrades, including up to 24GB of GDDR7 memory for flagship model. With retail availability set for March and April, CES 2025 attendees are already getting an advanced look at several laptops featuring the GPUs.
The flagship RTX 5090 laptop GPU boasts a staggering 10,496 CUDA cores across 84 Streaming Multiprocessors — nearly matching the desktop RTX 5080 in raw specs. Equipped with 24GB of VRAM using 3GB GDDR7 modules, it operates on a 256-bit memory interface.
The RTX 5080 laptop GPU steps down to 7,680 CUDA cores (60 SMs) and 16GB of memory, matching its predecessor in capacity. It still delivers solid AI performance at 1,334 TOPS, with a flexible TGP range of 80W to 150W.
Meanwhile, the RTX 5070 series is split into two models: the RTX 5070 Ti laptop GPU with 5,888 CUDA cores and 12GB of memory, and the base RTX 5070 laptop GPU, which drops to 4,608 cores and 8GB of VRAM.
Also Read: Top 10 Best Video Games Set In The Middle East
Efficiency is a focal point for these GPUs. NVIDIA claims that the RTX 5070 laptop GPU, running at 50-100W, can match the performance of the desktop RTX 4090 while using half the power. Blackwell GPUs also bring updates to NVIDIA’s Max-Q technology, designed to optimize power efficiency for laptops. Key advancements include Advanced Power Gating, which shuts down inactive GPU sections, and Low Latency Sleep, allowing the GPU to quickly enter and exit sleep states to save power during light use.
During its CES presentation, NVIDIA revealed the pricing structure for mobile Blackwell GPUs: Partner costs for the RTX 5090, RTX 5080, RTX 5070 Ti, and RTX 5070 are $2,899, $2,199, $1,599, and $1,299, respectively. This pricing reflects what manufacturers pay, so the final cost for laptops featuring these GPUs will be higher.






News
LUVED Is A New Curated Preloved Marketplace For The UAE
Sellers keep 100 percent of every sale and AI can build a listing in five seconds — though the app’s smartest tools are still coming.

Secondhand shopping has become mainstream in the UAE, but the experience is still scattered across resale sites, social media and informal group chats. LUVED, a mobile-first marketplace that launched in Dubai this month, is betting it can pull that activity into one place — and that the thing buyers and sellers actually want is not more inventory, but trust.
The app trades in what it calls circular luxury: preloved fashion and lifestyle pieces across men’s, women’s and children’s categories, bought, sold or given away peer to peer. Its main pitch is economics, with sellers keeping 100 percent of every sale under a zero-commission, fast payout model, while buyers are promised vetted pieces at lower prices.
Where LUVED is staking its reputation is verification. Sellers pass a KYC check, and items run through a two-layer authentication system powered by Entrupy that pairs instant AI screening with human expert review for high-value pieces. Authenticity certificates travel with each item, payments sit in escrow, and a buyer-protection package the company calls The Safety Net adds a 48-hour return window and dispute resolution. Door-to-door logistics removes the in-person meetups that make most resale deals awkward.
An in-app assistant called Luvbot — offering selling insights and demand-based recommendations — is soon to be introduced to the platform. Other features include autofill and dynamic pricing that lets users build a listing in as little as five seconds from three photos, plus a swipe-based feed, story-style drops and in-app chat in English and Arabic. Finally, a gifting layer, Luved & Gifted, lets users pass items to others inside the app rather than sell them.
Also Read: Logitech’s New Folding Mouse Is Designed For Work On The Go
“After moving to Dubai, I saw how difficult it was to sell or even give things away,” says founder and CEO Shaima Sibtain. The friction is real, and so is the competition. In resale, trust is won transaction by transaction — and that is the test LUVED has set itself.
The app is live on the App Store now, with Google Play to follow. The company also plans to expand across the region, which will be the real test for a marketplace staking everything on trust.

LUVED Is A New Curated Preloved Marketplace For The UAE

Max Fashion Brings AI Virtual Try-Ons To Gulf Online Shoppers
Instagram Now Lets You Tune Its Algorithm, But There’s One Big Catch

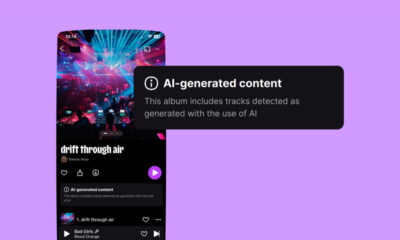
Deezer’s Free AI Detector Reveals What’s Hiding In Your Playlists

Logitech’s New Folding Mouse Is Designed For Work On The Go

2026 Crypto Trends: Bitcoin, ETFs & The Future Of Payments

At I/O 2026, Sundar Pichai Concedes AI Must Deliver Real Value
Instagram Now Lets You Tune Its Algorithm, But There’s One Big Catch
Logitech’s New Folding Mouse Is Designed For Work On The Go